
Table 3: 20 channel bark scale FFT
Next: FILTERBANK AND THE
Up:
A COMPARISON OF
Previous: Overview of the
The basis of the preprocessor used in previous work was the cube roots of a 20 channel bark scaled Fast Fourier Transform (FFT). The recognition rates for five different sets of initial weights are given in table 3. The mean of these will form the reference preprocessor, p20. The standard deviation ( s. d.) of these results is about 0.3%, which provides a lower bound for significant difference between preprocessors.
Table 3: 20 channel bark scale FFT
Increasing the dimensionality of the preprocessor output may allow it to carry more information at the expense of increasing the computation needed in the preprocessor and the recogniser. More training data is needed if the added channels contain noise, to avoid the fitting of the model to this noise. Table 4 shows the effect of a factor of three in the number of number of channels used, there is no discernible trend.

Table 4: Dimensionality of input
Table 5 shows the effect of varying the compression function applied to the channels. pc1 is no compression, p20 is the standard cube root compression, pc5 is a fifth root compression and pln is the conventional logarithmic compression. pc1 shows that it is important to use some form of compression to reduce the dynamic range, but there is little difference between the other three compression functions.
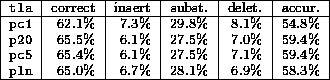
Table 5: Compression functions