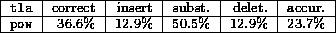
Table 2: Recognition rates: Power alone
Next: FFT BASED TECHNIQUES
Up: THE BASIC SYSTEM
Previous: The Recurrent Network
The space of commonly used preprocessors and combinations of these is too large to search exhaustively. As a simplifying assumption, some representation of the short term power spectrum was taken to be the most important feature. These representations were normalised and a separate power channel was added which was common to all preprocessors. A common feature of preprocessors for hidden Markov models is to use the difference of adjacent frames as extra input to the recognition system. This was thought to be unnecessary in the recurrent net case as the equivalent information may be computed by storing the previous input in the state vector.
The results will be presented in tabular form using a three letter acronym ( tla) to refer to the preprocessor and giving the percentage correct and the percentages of insertion, substitution and deletion errors. In addition the accuracy defined as 100% minus the number of insertion, substitution and deletion errors is given. Table 2 gives the basic recognition rates when only the power channel is used ( pow).
Table 2: Recognition rates: Power alone