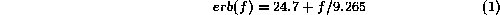
Next: LPC BASED TECHNIQUES
Up:
A COMPARISON OF
Previous: FFT BASED TECHNIQUES
Two studies were performed to test whether a preprocessor modeled on the human auditory system would be particularly suited to the recurrent network.
The first stage of auditory processing is spectral decomposition which is commonly simulated by a bank of band pass filters. Data from psycho-physical experiments on human subjects indicate the equivalent rectangular bandwidth of these filters vary roughly in proportion to the center frequency of the filter in accordance with the following equation modified from [5].
In order to provide an input frame for the network every 16ms, the output of each filter in a bank of such filters is Hamming windowed and then the cube root taken of the energy integrated across time. Though this is a rather crude method of collapsing the filter output, rows c20 and c36 in table 6 show satisfactory results for a 20 and 36 channel implementation of this spectral decomposition stage using 4th order Butterworth filters. These results confirm that a front end based on auditory parameters can perform very well. This is as would be expected given the theoretical similarity to the bark scaled FFT preprocessor which is already based on parameters from the human auditory system.
The second stage of auditory processing involves some form of magnitude compression and then adaptation with respect to signal level both across time and across frequency. This adaptation is required in order to cope with the very great variation in signal level encountered in the environment. The results fed in table 6 are from a implementation of such a system including filtering, pure logarithmic compression and rapid level adaptation. These results though reasonable were disappointing when compared to other preprocessors.

Table 6: Filterbank and Auditory model recognition results
This poor performance could be due to two factors. Firstly adaptation combined with the pure logarithmic compression could be performing an excessive normalisation of the input signal giving rise to an over emphasis of small features in the signal. To prevent excessive normalisation we propose to implement a limit on adaptation determined by the recent signal level. Psycho-physical data suggest such a time varying adaptation limit exists in the the human auditory system.
The second cause of the poor performance could be the spectral sharpening included in this more complete simulation to model the effect known as two-tone suppression in hearing. Current networks are limited to a small number of input channels. In this case the sharpening can result in a spectral feature being entirely contained in one channel of network input. As a result of this, small variations in the position of spectral features such as formants can result in a feature moving completely from one channel to another. This again brings about an over-emphasis of small variations in the input. Further tests will be necessary with either this sharpening removed, or perhaps the input vector to the network smoothed. In the longer term, however, when using this type of spatially organised input, the network should probably be adapted to somehow associate points adjacent in the input frame.
Next: LPC BASED TECHNIQUES
Up:
A COMPARISON OF
Previous: FFT BASED TECHNIQUES